Distributed Machine Learning Fundamentals: Intro
David Crawford / January 31, 2025

![]()
What I seek to share with this series of posts is the absolute fundamental knowledge needed to wrap your head around distributed machine learning. There are tools out there that do everything for you behind the scenes, and they're great for making this technology so accessible. But because the underlying mechanics are so complex, when things go wrong it's really hard to troubleshoot. This series of posts will help to give you some basic understanding of what's going on behind the scenes, so that you can make better decisions about what tools to use, how to use them, and you'll sound really smart doing it.
Our use case
Wowed by all of the fancy models being produced every week it seems, and the agency offered by locally hosting them with products like webAI, I wondered how I could get by without a super computer. Luckily, running inference on these advanced models doesn't take much more than a Raspberry Pi in some cases. But what if the model doesn't do what I need it to do? What if I wanted it to do something really niche, teach it something new or not publicly available?
I always wanted my chatbot model to be able to talk to me like a pirate.

If we take a model like Mistral-7B-v0.3-4bit, which is a great model to train with when you don't have a lot of RAM, asking it to talk like a pirate is...lackluster:
mlx_lm.generate --model ../Mistral-7B-Instruct-v0.3-4bit --prompt "Tell me about greek and roman history like a pirate"
==========
Ahoy matey! Let's set sail through the annals of Greek and Roman history, like a ship navigating the vast sea of time!
First, we'll anchor at the shores of ancient Greece, in the cradle of Western civilization. The Greeks, they were a clever bunch, with city-states like Athens and Sparta leading the charge. Athens, known for its wisdom, was home to philosophers like Socrates, Plato...
==========
Prompt: 17 tokens, 85.875 tokens-per-sec
Generation: 100 tokens, 37.294 tokens-per-sec
Peak memory: 4.119 GB
It does okay. It knew to say "Ahoy matey!" But really drops the ball on pirate grammar as the sentences continue.
We have two options to fix this:
- RAG (Retrieval-Augmented Generation)
- Fine Tuning
RAG - Better for Variety
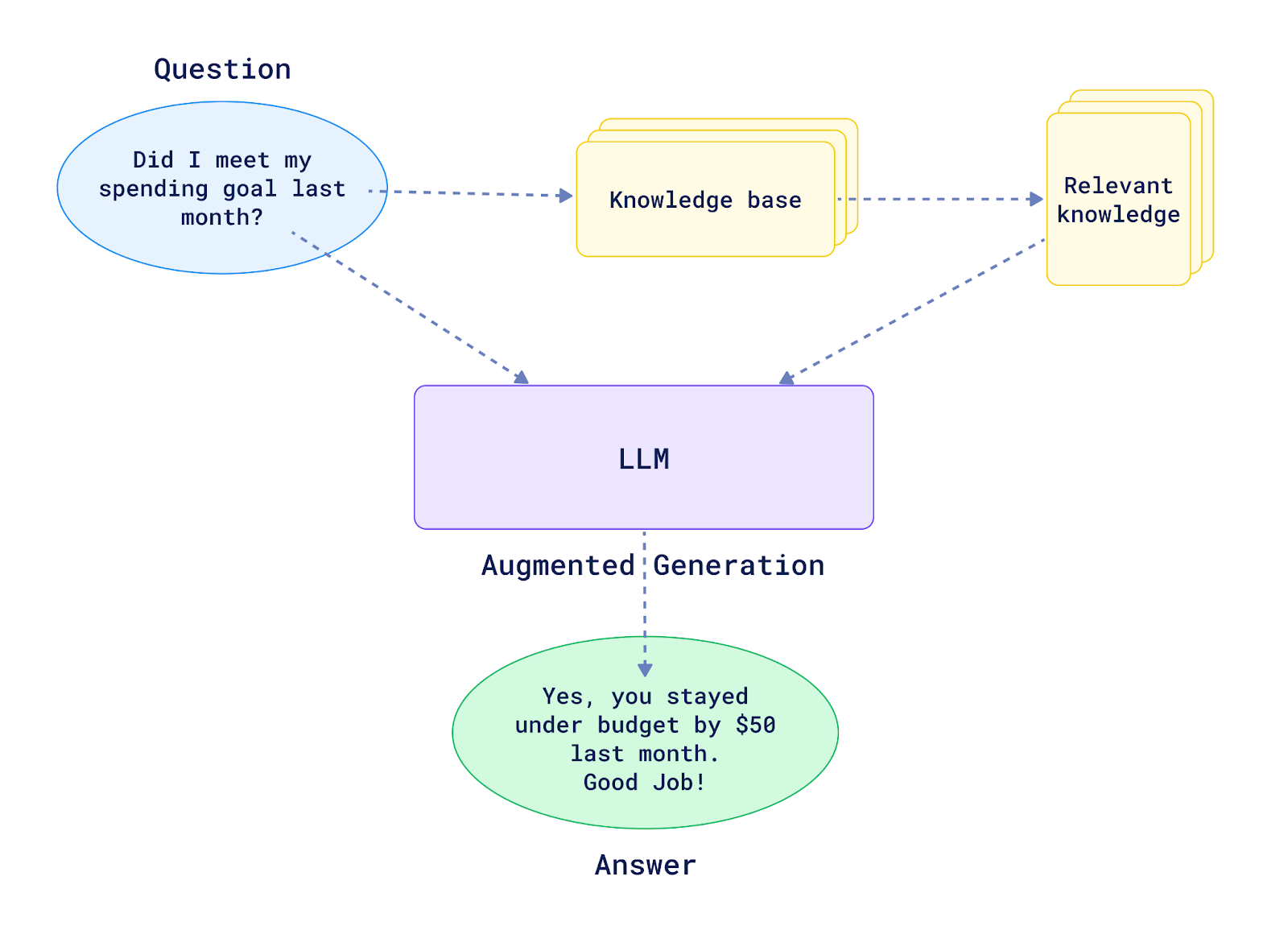
With a RAG, we can give our model access to a Vector or Graph database that houses random information that it otherwise wouldn't know, like company data, live metrics, or to oversimplify things, whatever suits a google spreadsheet really well.
Fine Tuning - Better for Specialization
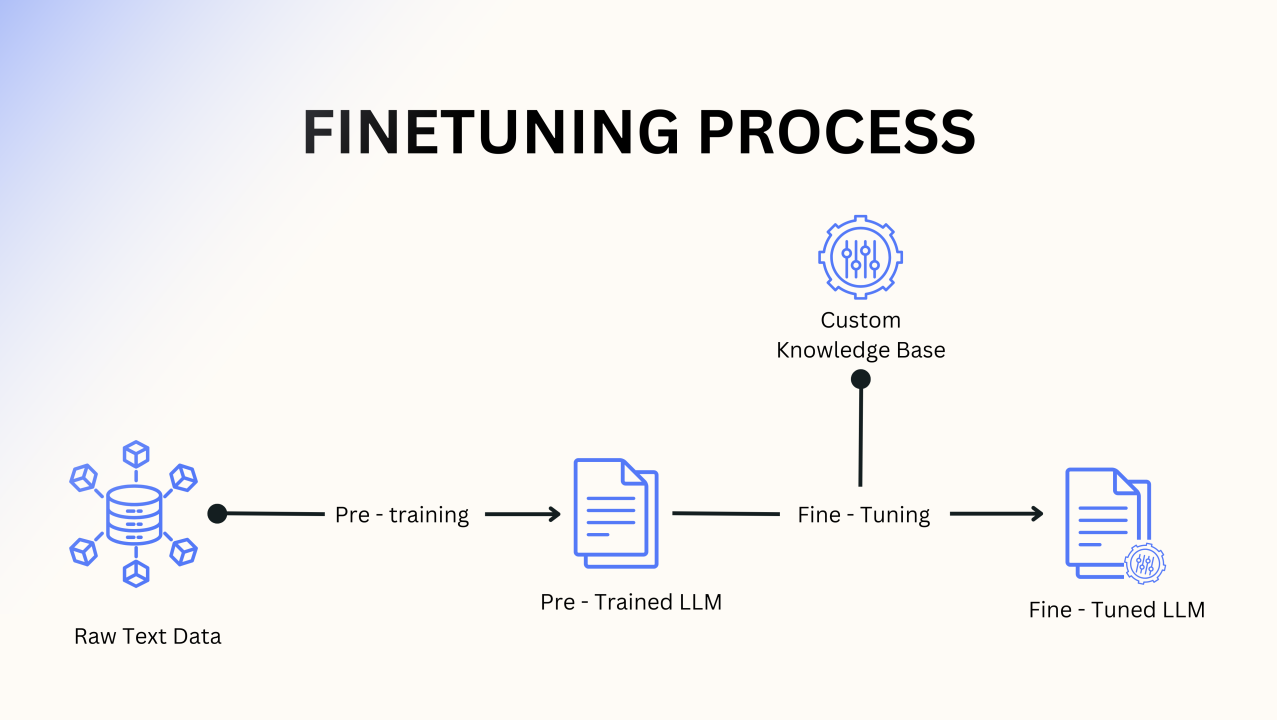
Fine tuning essentially means taking an existing model and training it on a new dataset that is more specific to the task you want it to perform. The output of fine tuning might be safetensor files, and you could fuse them to the model to output an entirely new model, or keep them separate as an adapter. This is better suited, in the case of a chat model, for teaching the model a new language, writing style, or commiting new information to the model itself.
Since we want to teach the model how to speak differently, fine tuning is the way to go
So can we do any of this without a super computer? Absolutely. For fine tuning, we would need a dataset, a model to fine tune, and...enough RAM to support the training process. Oops! Does that mean we need a super computer to fine tune a big model?
No

Distributed machine learning lets us take an otherwise "too large" model and distribute the workload across a bunch of bargain bin computers.
Let's assume you're already really bored by now and just want more bullet points. Here's our agenda for this series, and what each post will be about:
- Introduction (this post) - The bird's eye view, and high level questions and requirements to consider if this is applicable to you
- Preparing a Model with MLX - Setting up MLX and running inference on a model to establish a baseline. Otherwise, how will we know that a distributed workload sped anything up?
- Dataset Preparation - Getting the pirate grammar formatted for fine tuning. Curating data is incredibly integral to machine learning. If you don't get this right, you will fail to get any good results
- How to setup MPI - Everything you need to know to get MPI synchronizing processes on multiple computers. We'll walk through SSH, Hosts, Thunderbolt, and how ChatGPT doesn't have any answers to the problems you'll likely face
- Distributed Fine Tuning - Combine everything we've learned to fine tune a model across multiple computers
- Next Steps - The limitations of our fundamentals, and where to go from here to get things to be more sophisticated
Let's get started.
Introduction

Is distributed machine learning right for you? Consider these questions:
- Is training and fine tuning taking too long for you on your current setup?
- Do you have multiple computers available?
- Do you have a dataset that is too large to fit in memory?
- Are you applying for a job at NVIDIA and need to know more about MPI?
If you're going to follow along closely with the code in this series, you'll need the following:
- 1 (preferrably 2) or more Apple Silicon Macs (We're using MLX which doesn't work on anything else)
- A thunderbolt (preferably thunderbolt 4) cable
If you don't have these things, you'll still leave with fundamental knowledge that you can apply to other tech stacks. The underlying principles are the same.
The Bird's Eye View
-
When we fine tune a model, we're giving it new information and testing it on that information to see if it's learned anything
-
When we distribute the fine tuning process, we're testing each computer and averaging their results, or gradients
You can distribute the work using a lot of methods, but one of the most common is MPI (Message Passing Interface). MPI is one of many standards for synchronizing processes across multiple processors and computers. Instead of a game of telephone, where messages get distorted as they pass along, it's more like a synchronized group chat where all nodes share their updates and gradients in parallel.
The more complex the model, the more complex the weights, and therefore the more bandwidth you need to share the weights across your computers. If you distribute your training across wifi, you'll probably negate the entire benefit of distributing the work in the first place. This is why I prefer thunderbolt 4 which has more than enough bandwidth.
Up Next
Are you still interested? My next post will have considerably less walls of text, and a lot more code. We'll walk through getting MLX installed, choosing a great model to work with, and running inference on it to establish our baseline:
Part 2 - Preparing a Model with MLX