Distributed Machine Learning Fundamentals: Dataset Preparation
David Crawford / February 06, 2025

![]()
This post is part 3 of my Distributed Machine Learning series, you can go back to any of the posts that are published below:
- Introduction
- Preparing a Model with MLX
- Dataset Preparation (👈 this post)
- How to setup MPI
- Distributed Fine Tuning
- Next Steps
In this post, we will be discussing how to prepare a dataset for distributed machine learning.
In our current problem, we want our model to talk like a pirate really well, and not just use a couple pirate words at the beginning of its response and call it good.
As evidenced by running inference on the model we downloaded in the last post, we get this result:
mlx_lm.generate --model ../Mistral-7B-Instruct-v0.3-4bit --prompt "Tell me about greek and roman history like a pirate"
==========
Ahoy matey! Let's set sail through the annals of Greek and Roman history, like a ship navigating the vast sea of time!
First, we'll anchor at the shores of ancient Greece, in the cradle of Western civilization. The Greeks, they were a clever bunch, with city-states like Athens and Sparta leading the charge. Athens, known for its wisdom, was home to philosophers like Socrates, Plato
==========
Prompt: 17 tokens, 88.261 tokens-per-sec
Generation: 100 tokens, 36.407 tokens-per-sec
Peak memory: 4.119 GB
In order for the model to get smarter, and to learn a new dialect, we outlined in the introduction post that fine tuning is the key. Fine tuning is the process of adding more information to a model. So, in our example, what kind of information do we need to provide? We need examples of pirate grammar, of course! And we need a lot of it. So, how do we do that?
Going Shopping for Data
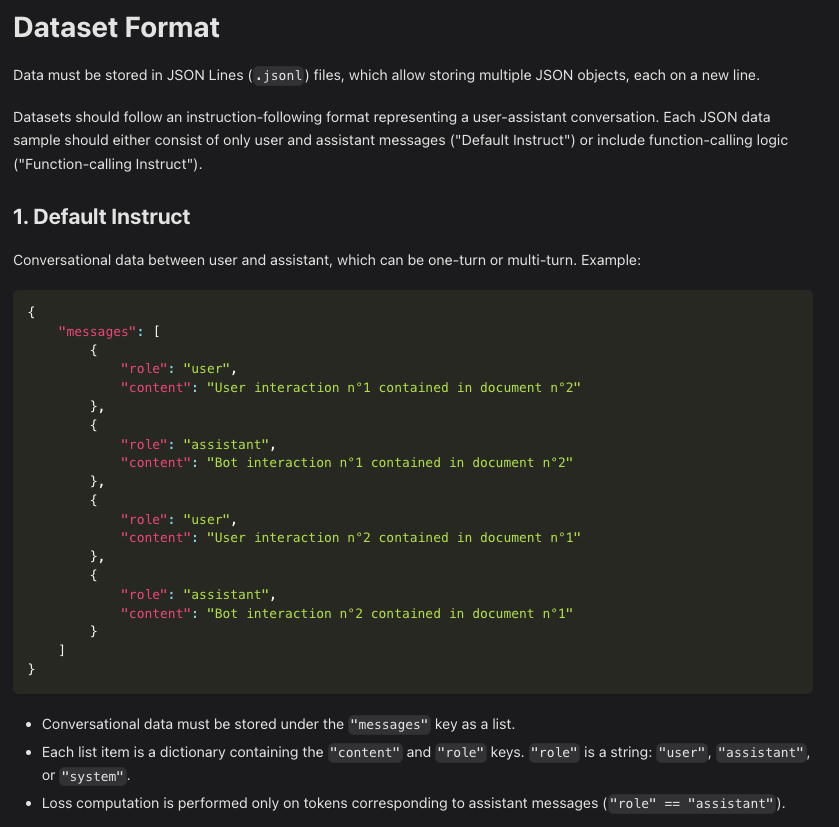
The key to getting good training results, is a good dataset. In our case, we're expecting to prompt our model with a question of some kind, and we expect it to give an answer in a certain way. This means that the best type of data to fit this is a lot of question and answer prompts.
The dataset we'll use in this post can be downloaded from here. This dataset is a collection of 15,000 question and answer pairs, all in pirate speak, and is organized like this:
| Instruction | Context | Response | Category |
|---|---|---|---|
| Please summarize what Linkedin does. | LinkedIn (/lɪŋktˈɪn/) is a business and employment-focused social media platform | Linkedin be a social platform that business professionals create profiles on and network with other business professionals. It be used to network, career development, and for jobseekers to find jobs. Linkedin has over 900 million users from over 200 countries. Linkedin can be used to post resumes/cvs, organizing events, joining groups, writing articles, publishing job postings, posting picture, posting videos, and more! | summarization |
So, does this mean we can just start fine tuning? No. We need to check our model's documentation first. This is where the practice of reading comes in handy:
We can see here that our dataset is actually already in the .jsonl format.
In light of this, you might be tempted to run this simple command to begin fine tuning:
mlx_lm.lora --train --model ../Mistral-7B-Instruct-v0.3-4bit --data databricks-dolly-15k-arr.jsonl
This is a pretty common method of training. LoRA (Low-Rank Adaptation) is a lightweight method of training that helps us adjust large models to new contexts, which we need for fine tuning to avoid having to retrain the entire model on its original dataset. You can read more about it here.
The command above is great and easy, but it won't work, and the error is interesting:
raise ValueError(
"Training set not found or empty. Must provide training set for fine-tuning."
)
ValueError: Training set not found or empty. Must provide training set for fine-tuning.
What does that mean? The training data is right there! Well, actually the problem is that we need to point it to a directory instead, and call it train.jsonl. So we do that and try again and get:
ValueError: Validation set not found or empty. Must provide validation set for fine-tuning.
Ok, so what's a validation set? Why doesn't the pirate dataset already come with this?
Training and Validation
When a model is trained on a bunch of data, it's important to know how well it's doing. This is where the validation set comes in. The validation set is a subset of the training data that the model doesn't see during training. This is important because if the model sees the same data during training and validation, it can memorize the data and not actually learn anything. This is called overfitting, which is an important terminology to know for model training and fine tuning.
In the real world, we might liken this to rote memorization. If you memorize a bunch of facts for a test, you might do well on only the questions you effectively memorized. But if you're asked a question that's similar to what you memorized, but not exactly the same, you'll get it wrong.
So how do we take the data and divide it up 80/20? This is actually a great task for your favorite AI tool like ChatGPT, which can spit out a python script that does exactly what we need:
import json
import random
import argparse
# Parse command line arguments
parser = argparse.ArgumentParser(description='Split a JSONL file into train and valid sets.')
parser.add_argument('input_file', type=str, help='Path to the input JSONL file')
parser.add_argument('train_file', type=str, help='Path to the output train JSONL file')
parser.add_argument('valid_file', type=str, help='Path to the output valid JSONL file')
args = parser.parse_args()
# Read the input file
with open(args.input_file, 'r') as f:
lines = f.readlines()
# Shuffle the lines
random.shuffle(lines)
# Calculate the split index
split_index = int(0.8 * len(lines))
# Split the lines into train and valid sets
train_lines = lines[:split_index]
valid_lines = lines[split_index:]
# Write the train lines to train.jsonl
with open(args.train_file, 'w') as f:
for line in train_lines:
f.write(line)
# Write the valid lines to valid.jsonl
with open(args.valid_file, 'w') as f:
for line in valid_lines:
f.write(line)
print(f"Split {len(lines)} lines into {len(train_lines)} train and {len(valid_lines)} valid lines.")
So we run this with our data like so:
python split.py databricks-dolly-15k-arr.jsonl train.jsonl valid.jsonl
Split 15011 lines into 12008 train and 3003 valid lines.
Then we take our two new .jsonl files and put them into a data folder, and retry our training command:
mlx_lm.lora --train --model ../Mistral-7B-Instruct-v0.3-4bit --data data
And...we get another error!
ValueError: Unsupported data format, check the supported formats here:
https://github.com/ml-explore/mlx-examples/blob/main/llms/mlx_lm/LORA.md#data.
The link mentioned in the error message tells us that the pirate dataset isn't quite structured correctly for LoRA to use. So, we need to convert it to the correct format as well in our python script.
It's currently structured like this:
{"instruction": "(stuff)", "context": "(stuff)", "response": "(stuff)", "category": "closed_qa"}
And it needs to be like this for MLX:
{"messages": [{"role": "user", "content": "(stuff)"}, {"role": "assistant", "content": "(stuff)"}]}
So we tweak our script like so and try again:
import json
import random
import argparse
# Parse command line arguments
parser = argparse.ArgumentParser(description='Split a JSONL file into train and valid sets.')
parser.add_argument('input_file', type=str, help='Path to the input JSONL file')
parser.add_argument('train_file', type=str, help='Path to the output train JSONL file')
parser.add_argument('valid_file', type=str, help='Path to the output valid JSONL file')
args = parser.parse_args()
# Read the input file
with open(args.input_file, 'r') as f:
lines = f.readlines()
# Shuffle the lines
random.shuffle(lines)
# Calculate the split index
split_index = int(0.8 * len(lines))
# Split the lines into train and valid sets
train_lines = lines[:split_index]
valid_lines = lines[split_index:]
def format_line(line):
data = json.loads(line)
formatted_data = {
"messages": [
{
"role": "user",
"content": f"You are a helpful assistant.\n\n{data['instruction']}\n\nContext: {data['context']}"
},
{
"role": "assistant",
"content": data['response']
}
]
}
return json.dumps(formatted_data)
# Write the train lines to train.jsonl
with open(args.train_file, 'w') as f:
for line in train_lines:
f.write(format_line(line) + '\n')
# Write the valid lines to valid.jsonl
with open(args.valid_file, 'w') as f:
for line in valid_lines:
f.write(format_line(line) + '\n')
print(f"Split {len(lines)} lines into {len(train_lines)} train and {len(valid_lines)} valid lines.")
Finally, rerunning the training command we get this output:
Loading pretrained model
Loading datasets
Training
Trainable parameters: 0.047% (3.408M/7248.024M)
Starting training..., iters: 1000
Feel free to cancel it if you want, but now we know that the data is good to go.
The Takeaway
Shopping around can be fun when you're looking for cool datasets for your model to learn, but be prepared to put in a little work to get it formatted properly. There are other considerations we can make as well to take this a step further:
- Read the specs on the model you want to fine tune or train
- Don't forget to split your data into training and validation sets, a good rule of thumb is an 80/20 ratio
- Make sure the data follows the same prompt patterns you expect to use, for best results
- Use AI chat models to spit out some quick python scripts that parse through things, it's really easy
- If memory usage needs to be kept at a minimum, for the Mistral v0.3 model family, remove data that's longer than 2048 tokens or you'll get warnings during the training loops, and your RAM usage will spike, and the training will take longer
- Don't truncate data, it's better to remove it entirely, because it reduces the quality of the training data and the model will learn incorrect patterns
Next Steps
If all you cared about was fine tuning an MLX model, you could stop here in the series. You could, with one computer, fine tune whatever you want now with the fundamentals we've covered so far. And that's okay, because that's how distributed machine learning starts: with one machine. But it ends with two or more. We want to take it a step further and get multiple machines to run through the training together to greatly speed up the process.
In the next post, we'll learn how to start synchronizing multiple machines using MPI. After that, we'll combine all of the concepts we've learned and fine tune our model with our distributed setup.
Part 4 - How to setup MPI